Use Mac OS to generate speech files from text
Here’s a free (if you’ve got access to a Mac), quick method for creating spoken experimental stimuli, which I’ve implemented in this project and now use regularly in my lab. Hat tip to Richard Morey for suggesting this and writing a few lines of code that saves many hours of tedious voice recording.
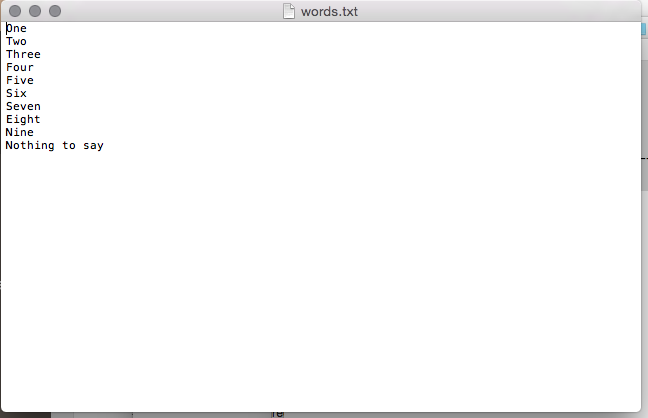
- Create a plain text file with the texts you want to create .wavs for entered on separate lines. Line break after each word or phrase that you want to generate a sound file for. Name your text file “words.txt”. It should look something like this one we recently used to generate audio files for a digit span task:

- Open iTerm, and navigate to the folder where your “words.txt” file is located. Here’s a lesson on how to navigate via command line. TLDR: the “cd” (current directory) command is what you need. cd .. will move you to the directory one above where you are. The “ls” command lists the folders in the current directory.
- Type the following into iTerm:
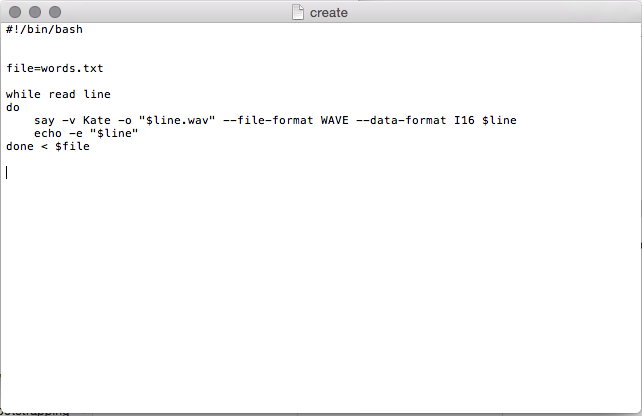
In a few seconds, the directory containing “words.txt” will also include a .wav file for each entry from “words.txt”.
This code uses the MacOS voice “Kate” (a female voice with a British accent). You can replace “Kate” with any voice available on your system by removing “Kate” from the code and typing your preferred voice instead.
Text-to-speech isn’t perfect. You want to check that your .wav files sound like the text you meant for them to sound like. Different voices sometimes pronounce the text in different ways, so one solution to weird-sounding speech is to try another voice. You can also try alternative spellings to get the right pronunciation.
3 thoughts on “Use Mac OS to generate speech files from text”
Thanks Candice. This is wonderful once you get it working.
I struggled a bit at first.
I think the default voice that comes with a Mac is Daniel. If you need to install Kate, you go to System Preferences|Accessibility|Speech and you can then inspect a range of voices to install.
My main problem was that I could not get the program to recognise the words.txt file. I think there are issues if you create your text in Word – there seem to be hidden characters. Fortunately, Richard Morey kindly sent me a working version that I could adapt, but even then, I found that if I just pasted words from a Word list into words.txt, the program would do odd things, like run them all together. Eventually I found that the answer was to use something like Notepad to create the list, and then be careful to paste and match format. Then, magically, it all worked brilliantly.
Thanks Candice.
There might be even an easier way to create a sound file from text in Mac OS. If you highlight the text you want to record in a .txt or .pages document, and click on the right mouse button, you should be able to select “import as an audio file to iTunes” (or something similar, it is in German on my computer). Then you can select the voice and listen to what the recording will sound like. This recording is in .m4a format, so you might have to convert it to .wav or .aiff in Amadeus or whatever sound editing program you prefer.
Best, Jan
Thanks, Jan, I didn’t know that! But it would still take quite a while to make a large batch of sound files using that method. If I need to create more than a few, struggling with scripting rapidly becomes worth the time.